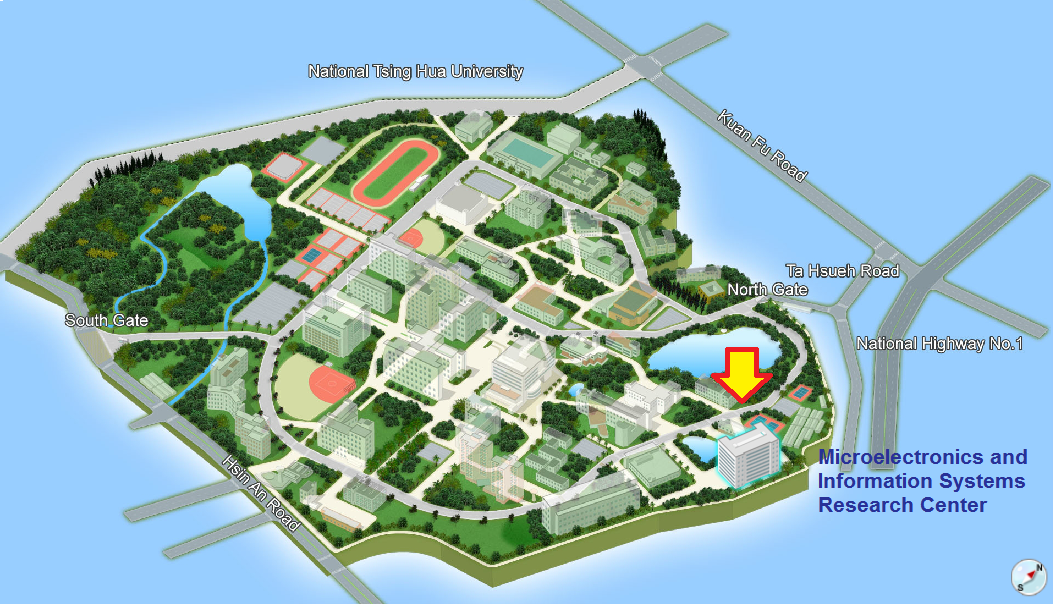
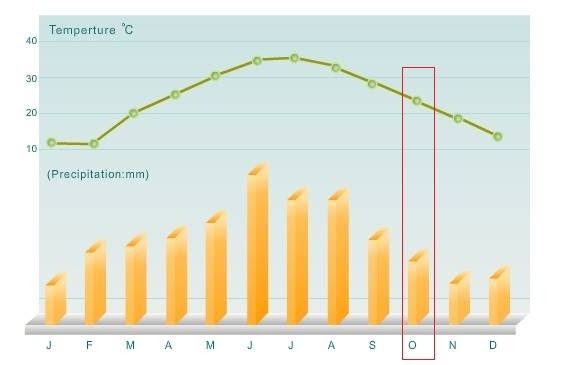
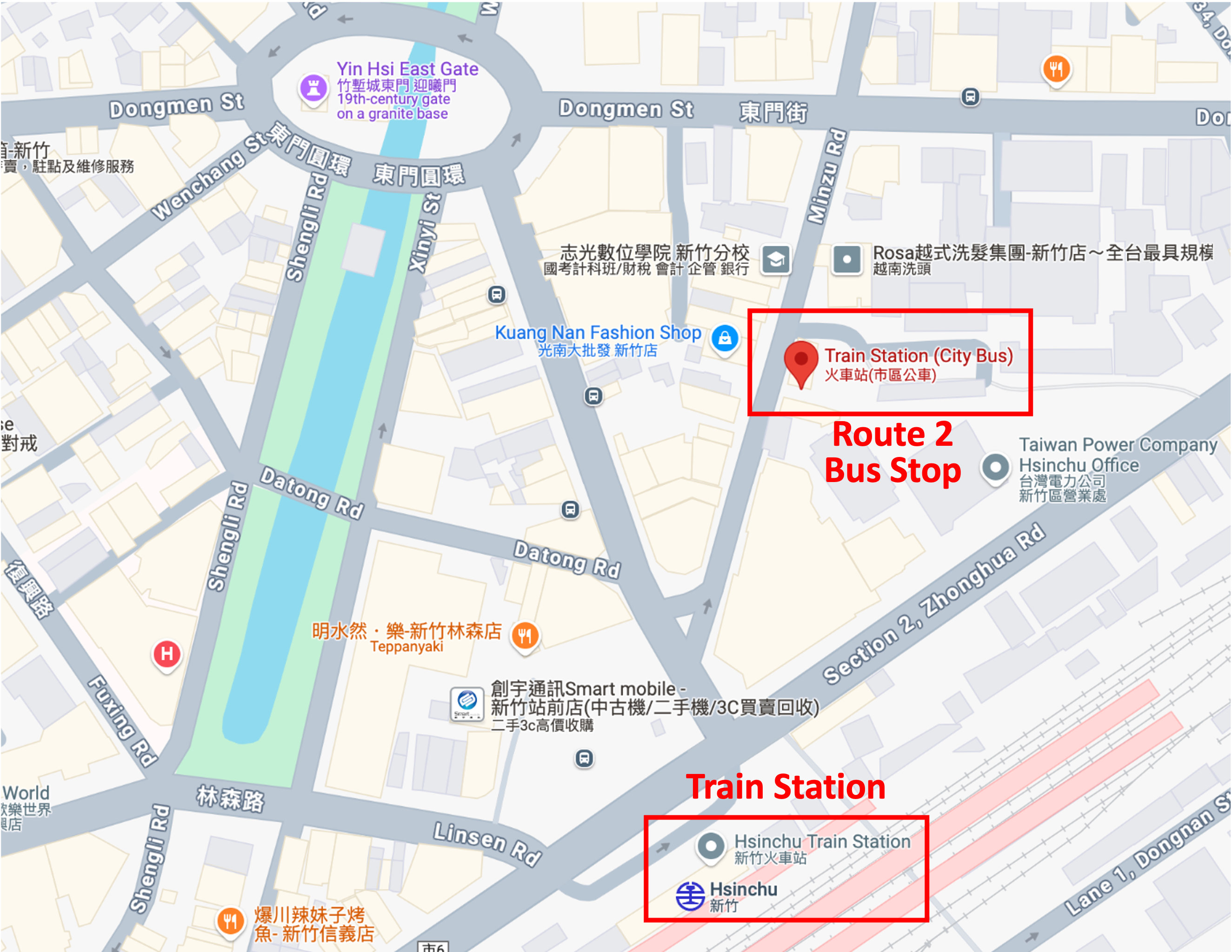
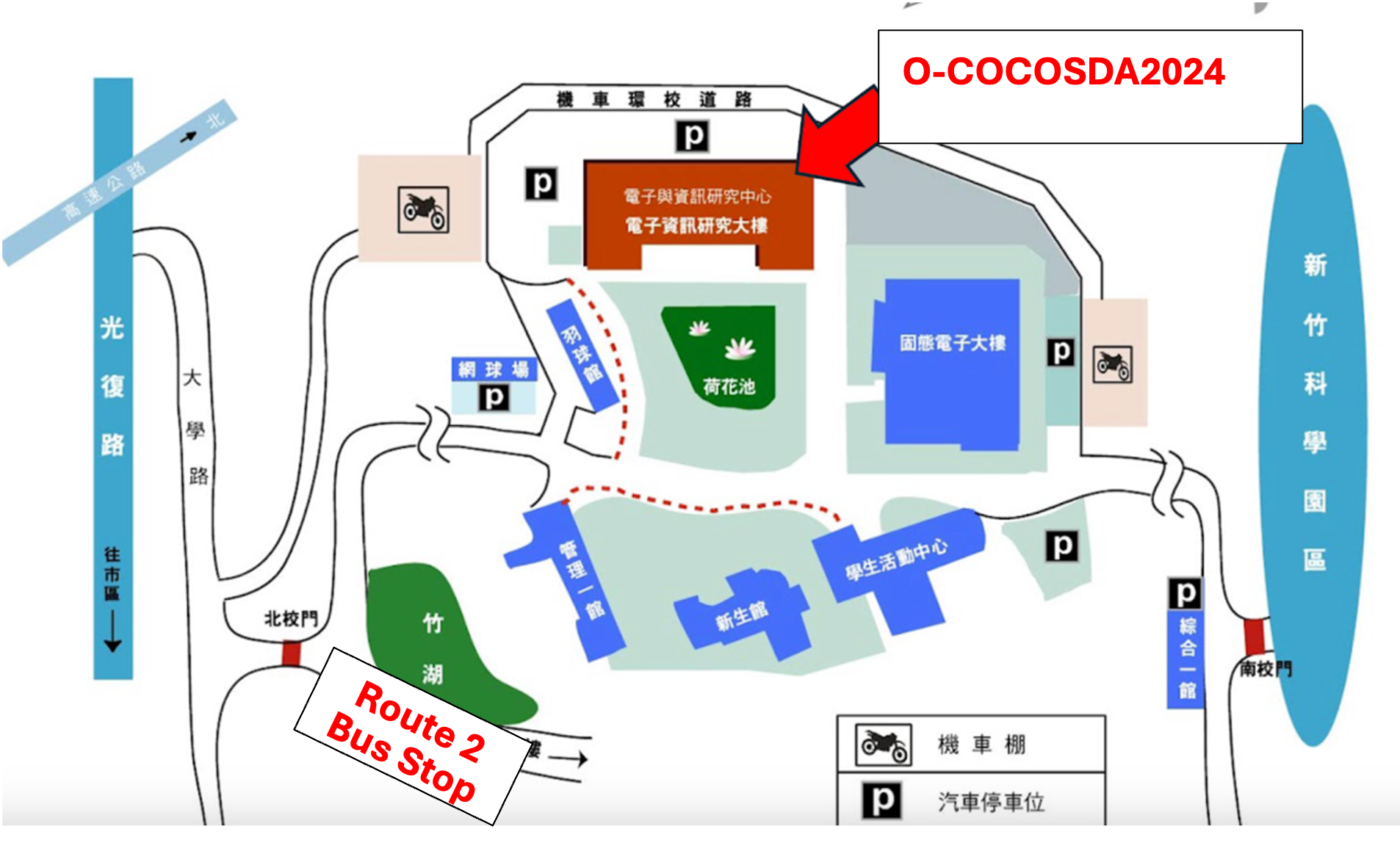
Transportation information has been updated.









O-COCOSDA 2024: The 27th International Conference of the Oriental COCOSDA will take place from October 17-19 in Hsinchu, Taiwan. Hosted once again by the National Yang Ming Chiao Tung University (NYCU), this conference will be held in-person. We kindly encourage your physical attendance to fully experience and engage with the event.
Oriental COCOSDA (O-COCOSDA), the Oriental chapter of COCOSDA, an acronym of the International Committee for the Coordination and Standardisation of Speech Databases and Assessment Techniques, was established in 1997. The purpose of O-COCOSDA is to exchange ideas, share information, and discuss regional matters on the creation, utilization, and dissemination of spoken language corpora of oriental languages and also on the assessment methods of speech recognition/synthesis systems as well as promote speech research on oriental languages.
The annual Oriental COCOSDA international conference is the flag conference of Oriental COCOSDA. The first preparatory meeting was held in Hong Kong in 1997 and then the past 26 workshops were held in Japan, Taiwan, China, Korea, Thailand, Singapore, India, Indonesia, Malaysia, Vietnam, Japan, China, Nepal, Taiwan, Macau, India, Thailand, China, Malaysia, Korea, Japan, Philippines, Myanmar, Singapore, Vietnam and India. The 27th Oriental COCOSDA Conference is returning to Taiwan and will be held on Oct. 17-19, in Hsinchu, Taiwan hosted again by the National Yang Ming Chiao Tung University (NYCU), Taiwan.
The organizers of O-COCOSDA 2024 invite all researchers, practitioners, industry partners and sponsors to join the conference. The O-COCOSDA venue provides a regular forum for the presentation of international cooperation in developing speech corpora and coordinating assessment methods of speech input/output systems for both academic and industry researchers. Continuing a series of 26 successful previous meetings, this conference spans the research interest areas of database development and assessment methods. We thank you for your support and look forward to welcoming you to the conference. Stay safe and healthy!
We are pleased to inform you that the conference will be held in-person. Your physical attendance is highly encouraged to facilitate the full experience of the event. However, if you encounter special circumstances (e.g., issues with visa applications), please discuss this with the organizers to seek approval for alternative arrangements.